2026
Unified Spatiotemporal Token Compression for Video-LLMs at Ultra-Low Retention
Junhao Du*, Jialong Xue*, Anqi Li, Jincheng Dai, Guo Lu
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2026
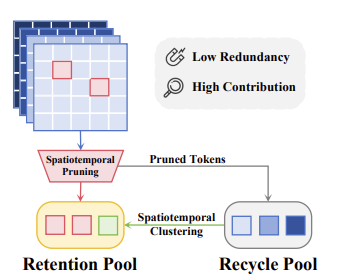
We formulate token compression for Video-LLMs as a unified spatiotemporal allocation problem under a global retention budget. The method preserves strong video understanding performance at ultra-low token retention without retraining.
Unified Spatiotemporal Token Compression for Video-LLMs at Ultra-Low Retention
Junhao Du*, Jialong Xue*, Anqi Li, Jincheng Dai, Guo Lu
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2026
We formulate token compression for Video-LLMs as a unified spatiotemporal allocation problem under a global retention budget. The method preserves strong video understanding performance at ultra-low token retention without retraining.